A³-FPN: Asymptotic Content-Aware Pyramid Attention Network for Dense Visual Prediction
Meng’en Qin, Yu Song, Quanling Zhao, Yinchen Liu, Mingxuan Cui, Zihao Liu, Xiaohui Yang (corresponding author).
Under review in IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), 2025
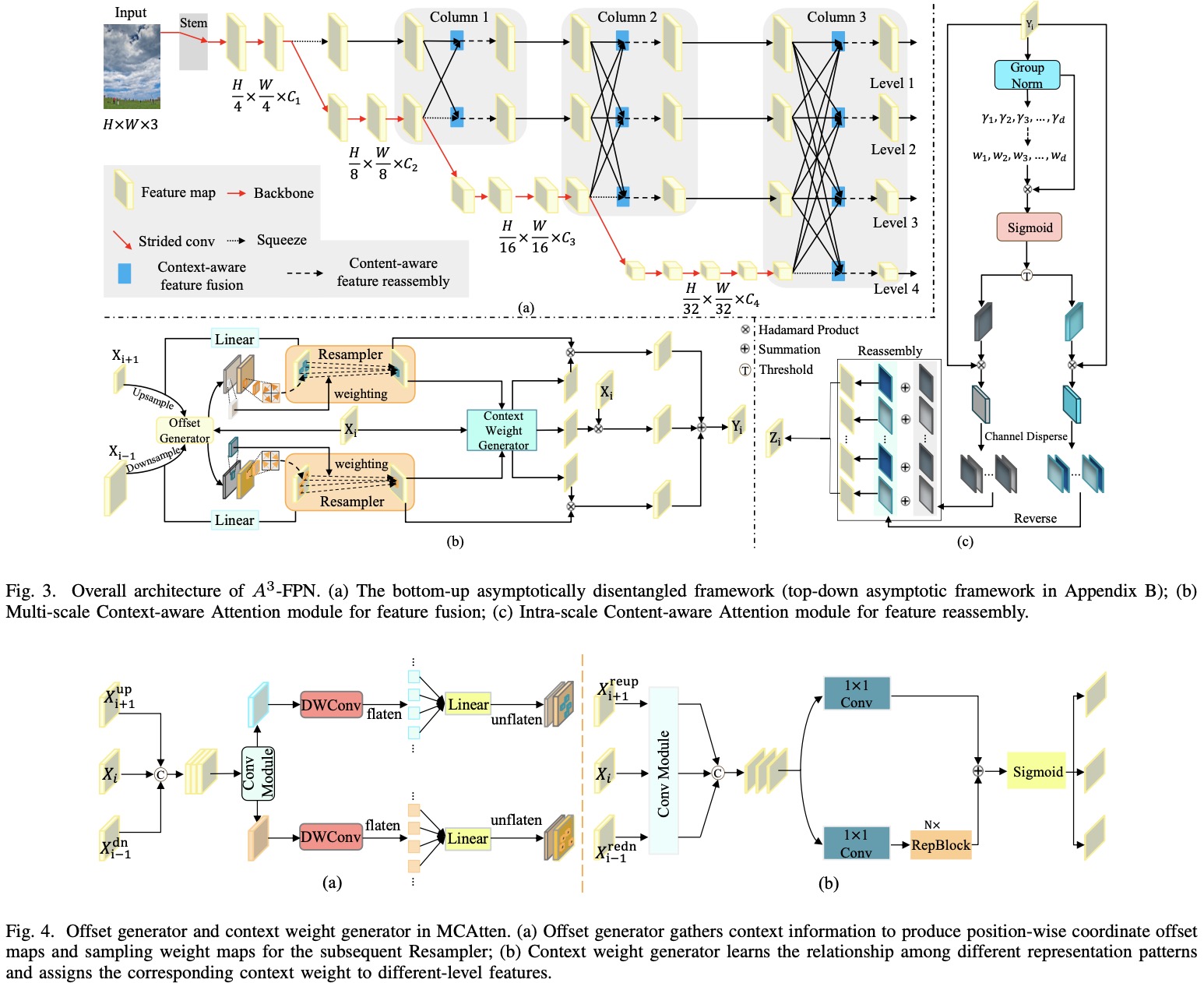
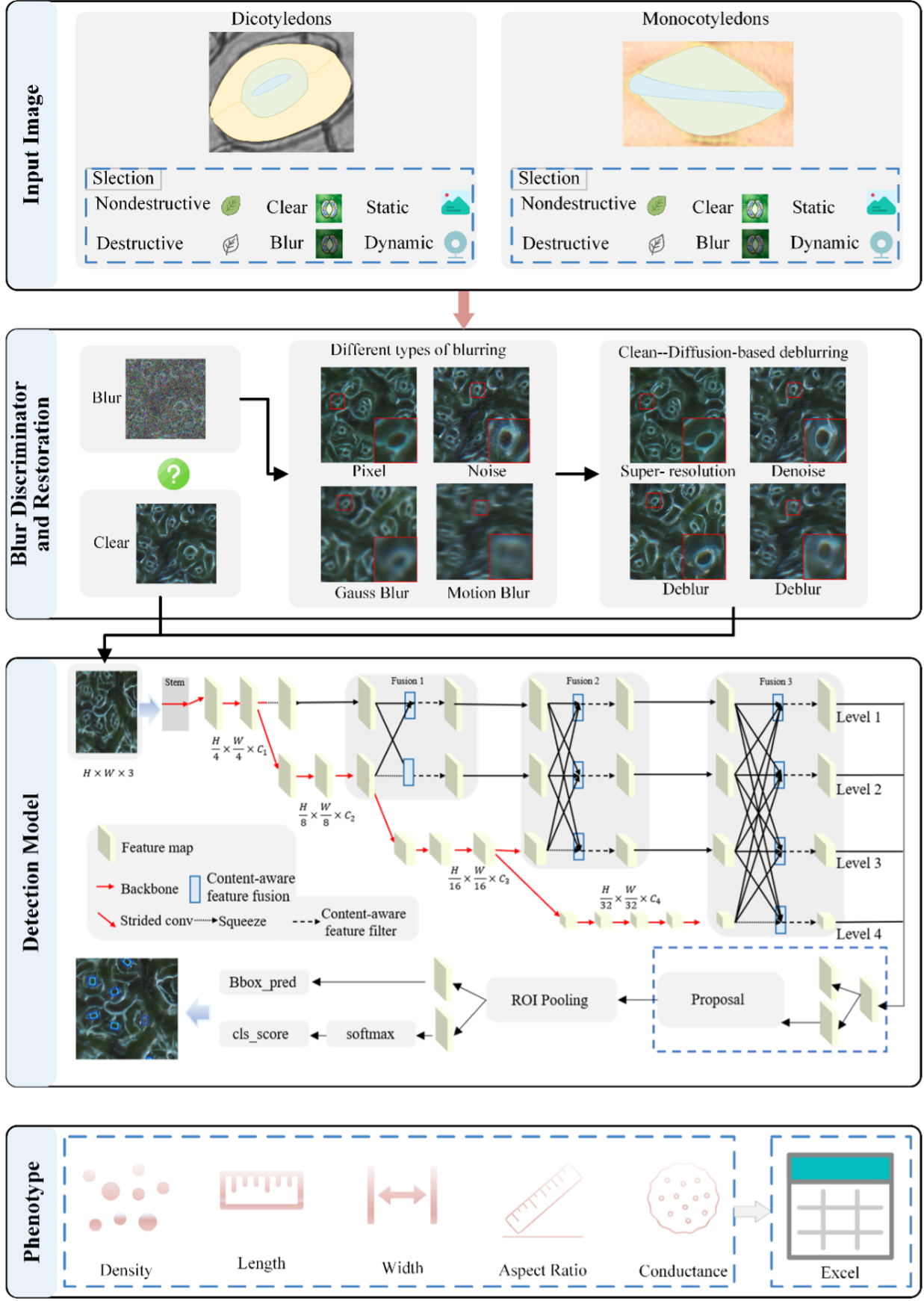
In this work, we identify three critical issues: information loss, context-agnostic sampling and pattern inconsistency in existing multi-scale feature fusion networks and operations. To tackle these issues, this paper proposes Asymptotic Content-Aware Pyramid Attention Network (\(\mathrm{A^3}\)-FPN). Specifically, \(\mathrm{A^3}\)-FPN employs a local-to-global convolutional attention network that gradually enables global feature interaction and disentangles each level from all hierarchical representations. In feature fusion, it collects supplementary content from the adjacent level to generate position-wise offsets and weights for context-aware resampling, and learns multi-scale context reweights to improve intra-category similarity. In feature reassembly, it further strengthens intra-scale discriminative feature learning and reassembles redundant features based on information density and spatial variation of feature maps. Extensive experiments on MS COCO and Cityscapes demonstrate that \(\mathrm{A^3}\)-FPN can easily yield remarkable performance gains on both CNNs and ViTs. Notably, when paired with OneFormer and Swin-L backbone, \(\mathrm{A^3}\)-FPN achieves 49.6 mask AP on MS COCO and 85.6 mIoU on Cityscapes. Furthermore, \(\mathrm{A^3}\)-FPN exhibits powerful capabilities in more precise detection and segmentation, particularly for small,cluttered, and dense objects.